What's a Preload Scanner?
A preloader is like a parser that scans the HTML file while the main parser is processing the HTML code. Its role is to look for resources like stylesheets, scripts or images (that also need to be retrieved from a server) and request them. Hopefully, by the time the HTML is parsed, those resources are already downloaded and ready to be processed.
Every browser has a primary HTML parser that tokenizes raw markup and processes it into an object model. The parser will pause when it finds a blocking resource, such as a stylesheet loaded with a <link> element, or <script> without an async or defer attribute.
Why does browsers block parsing and rendering of the page?
Ans: The reason for this is that the browser can't know for sure if any given script will modify the DOM while the primary HTML parser is still doing its job.
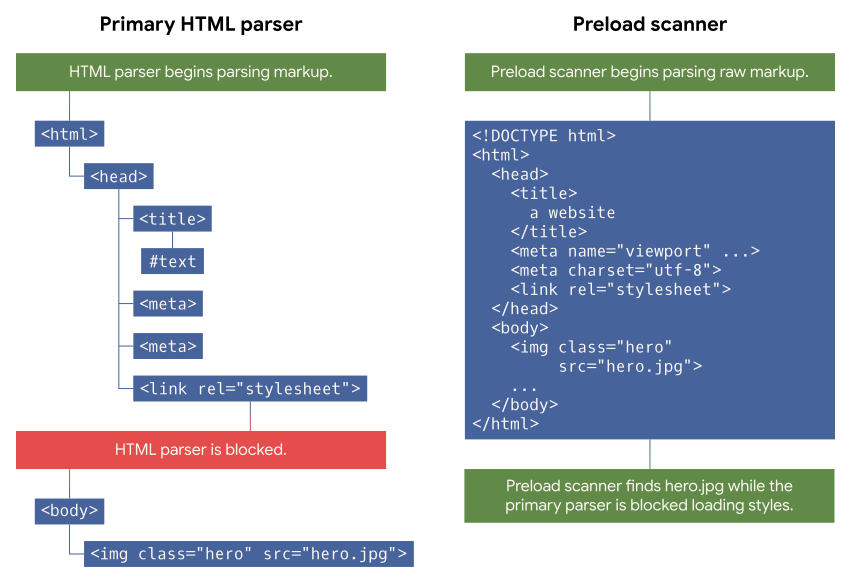
Fig. 1: A diagram depicting how the preload scanner works
in parallel with the primary HTML parser to speculatively load assets. Here,
the primary HTML parser is blocked as it loads and processes CSS before it
can begin processing image markup in the <body> element,
but the preload scanner can look ahead in the raw markup to find that image
resource and begin loading it before the primary HTML parser is unblocked.
A preload scanner's role is to examine raw markup in order to find resources to fetch before the primary HTML parser discover them.
CSS files block both rendering and parsing.