Bellman Equation
The page consists of two sections.
Bellman Equation Basics
An introduction to the Bellman Equations for Reinforcement Learning
Important Bellman Concepts
- STATE: a numeric representation of what the agent is observing at a particular point of time in the environment. (e.g., raw pixels on the screen)
- ACTION: the input the agent provides to the environment, which is calculated by applying a policy to the current state. (e.g., control buttons pressed, joystick)
- REWARD: a feedback signal from the environment reflecting how well the agent is performing the goals of the game. (e.g., coins collected, enemies killed)
Goal of Reinforcement Learning
Given the current state we are in, choose the optimal action which will maximize the long-term expected reward provided by the environment.
What Question Does the Bellman Equation Answer?
Given the state I'm in, assuming I take the best possible action now and each subsequent step, what long-term reward can I expect?
What is the VALUE of the STATE?
It helps us evaluate the expected reward relative to the advantage or disadvantage of each state.
Bellman Equation
For deterministic environments.
- a given state.
- the VALUE of a given state.
- means that all the actions available in the state we are in, we pick the action which is going to maximize the value.
- is the reward of the optimal action in state .
- is the discount factor.
- is the state after performing the action .
At each step, we need to know what the optimal action is.
Gamma
- Successful values range between 0.9 and 0.99.
- A lower value encourages short-term thinking.
- A higher value emphasizes long-term rewards.
Example

At , means we can get a reward of 1 if we take the action in state because it can get us to the green cell. because is the terminal state and there is no value associated with it.
Bellman Equation Advanced
For stochastic environment.
Bellman Equation Advanced for Reinforcement Learning
Markov Decision Process
State -> Action
We're in a state we choose an action, and now there are several possible states we could end up being in based on random probability.
Each possible state transition from an action has an exact probability and all the probabilities add up to 1.
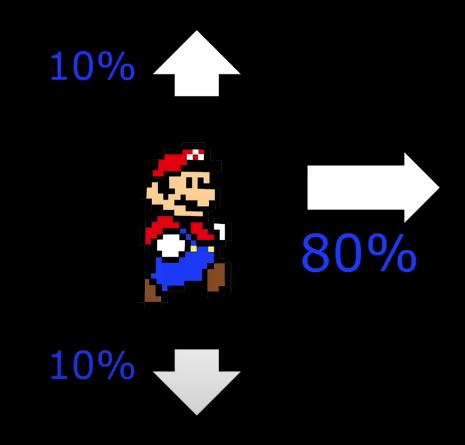
The probability of future transitions only depends on the present and the past doesn't matter.
New Bellman Equation
For stochastic environment.
- Loop through every possible state that we can transition to after taking a specific action.
- Multiply the VALUE of that state by its probability of occurring.
- Sum them all together.
means that we are looping all the that the optimal action could possibly lead us to.