Machine Learning Basics
What is Machine Learning?
Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.
Types of Machine Learning
Supervised
Task Driven (Regression/Classification)
We have labeled data - we know that the answer should be
Examples:
- Object tracking
- Image classification
Unsupervised
Data Driven (Clustering) No labelling - knowledge discovery
Examples:
- Detect abnormal behaviors
Semi-Supervised
Only some (usually a small amount of data) is labelled
- Half way between supervised and unsupervised learning
- Learn from labelled and unlabelled data
Reinforcement
Algorithms learn to react to an environment
Learn through interactive environment
Examples:
- Robot
- AlphGo
Data Splitting for Machine Learning
Training
It is the set of data that is used to train and make the model learn the hidden features/patterns in the data.
The training set should have a diversified set of inputs so that the model is trained in all scenarios and can predict any unseen data sample that may appear in the future.
Validation
The validation set is a set of data, separate from the training set, that is used to validate our model performance during training
The model is trained on the training set, and, simultaneously, the model evaluation is performed on the validation set after every epoch.
Testing
The test set is a separate set of data used to test the model after completing the training.
It answers the question of "How well does the model perform?"
Holdout Validation
The data set is separated into two sets, called the training set and the testing set.
Cross-Fold Validation
Pick up a number k which stands for the number of groups that the data set is going to be split into. If k=10, it would be called 10-fold cross-validation.
The general procedure is as follows:
- Shuffle the dataset randomly.
- Split the dataset into
kgroups. - For each unique group:
- Pick one group as a test set
- Take the remaining groups as a training set
- Fit the model on the training set and evaluate the model on the selected test set (from step i).
- Record the evaluation score and discard the model
Neural Networks
A computer system modelled on the human brain and nervous system - Built on simple, stacked operations
Typically have high number of parameters & lots of interconnections
Data propagates through the networks
- Input -> Intermediate Layers -> Output
- Similar to how we think the brain works

History
Initial research started in 1940's and 50's
Deep Learning
- Emerged in the late 2000's
- Win ImageNet competition in 2012 with "AlexNet"
- The dominant machine learning method across most domains
How Much Depth?
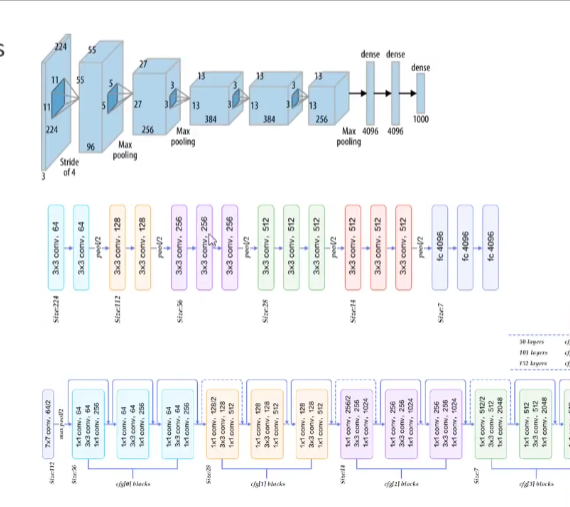
- AlexNet, 8 layers
- VGG10, 19 layers
- ResNet, 50 to 152 layers
Benefits diminish as we get deeper. i.e. going from 3 to 15 layers gives a huge gain, however, going from 100 to 500 doesn't add much
More Deep is More Better?
More depth gives
- Pros:
- Ability to learn higher level features -> a richer representation
- More parameters -> more representative power
- Cons:
- More parameters -> harder to learn & more likely to overfit
- More layers -> further for gradients to propagate
- Harder to fit networks in memory
- Need specialist hardware, and very long times to train
Deep Learning Pipeline
Common Pipeline:
- Pre-processing
- Resizing, filtering, noise reduction
- Input images (usually) need to be the same size
- Deep Learning
- Pass raw data to network
- Let the network learn its own representation and make the decision in one pass
How do we remove the human-driven feature extraction process?
Answer: It is being done in the network. The layers at the beginning of deep networks can perform feature extractions, then the later layers learn the classification (or other tasks)
Deep Learning: Pros and Cons
Pros
- Easy to extend model to multiple tasks, or adapt to new tasks (utilize image models in audio domain - sound wave image)
- No feature engineering
Cons
-
Models are huge compared to "traditional" approaches
- Millions vs Hundreds of parameters
- Requires more data, runtime, and memory
- Models are harder to interpret
- Explainable AI. Why did my model make this decision? Too many parameters
-
Get rid of feature engineering, but introduce network engineering
- Choose hyper parameters - what layers, how many, what parameters, etc.
- Can be very slow to iterate over these decisions.
- May not be possible to determine a truly "optimal" decision.