Simple Linear Regression
Definition
Often we want to find a relationship between two variables to:
- Predict behavior
- Explore relationships
The simplest way to achieve this is to assume a linear relationship
Assumptions:
- Predictors are independent (not correlated)
- Residuals form a gaussian/normal distribution (bell curve)
On a qq-plot, that means they should form a straight line, for a histogram it means we should see a normal (bell) curve.
# plot qq-plot
statsmodels.api.qqplot(model.resid)
print(model.resid)

# plot histogram
fig = plt.figure(figsize=[8, 8])
ax = fig.add_subplot(1, 1, 1)
ax.hist(model.resid, 20)

offset + coefficient x variable
Minimize the Error
Try my best to estimate and given a set of observations, and , so they can give the best given
In practice, our data is rarely on a straight line
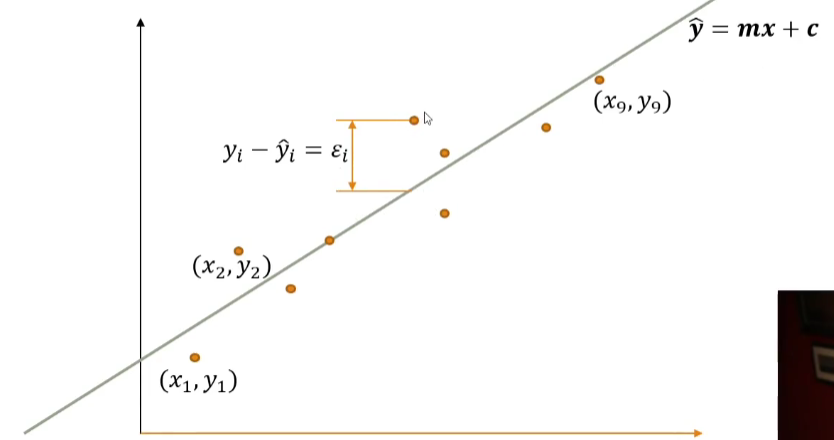
Point in our regression line is given by
is the predicted value, is the ground truth (observed) value. The difference between and is called the error (residual) ~ . We assume the residual is normally distributed around 0
The goal is to find the values of and that minimize the sum of the square of the errors
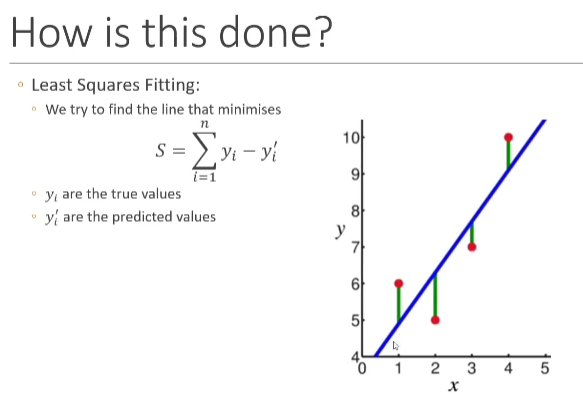
Minimum requirement: the number of training samples should be much larger than the number of terms we are trying to estimate.
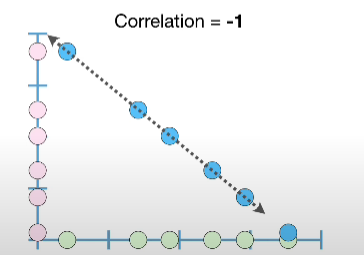
Correlation
Definition: It describes the degree (ranges from -1 ~ 1) that two variables move in coordination with one another. If two variables move in the same direction, then those variables are said to have a positive correlation. If they move in opposite directions, then they have a negative correlation. It controls the strength and direction of the relationship.
We can quantify the strength of the relationship with correlation. The sign (+/-) represents the direction of the relationship.
- -1, as one value increases the other decreases
- 0, no linear relationship, statically independent. It can still have other types of relationship.
- +1, increase and decrease together
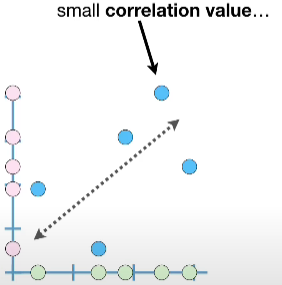
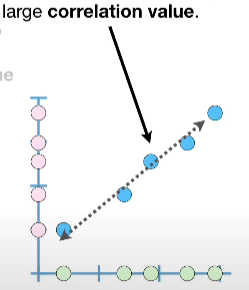
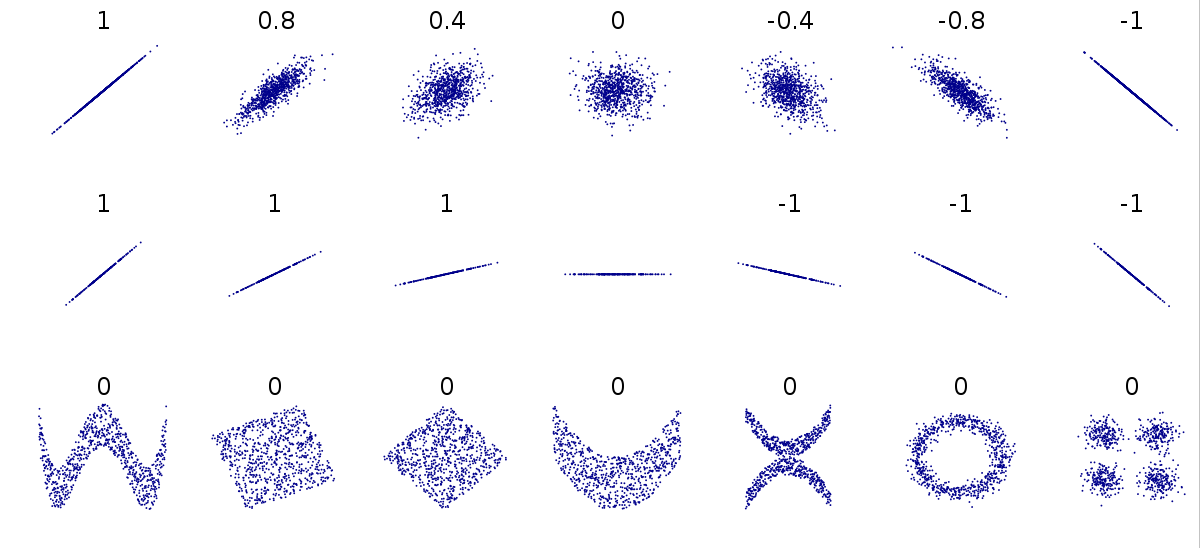
When the relationship cannot be represented with a straight line (linear relationship), correlation = 0.
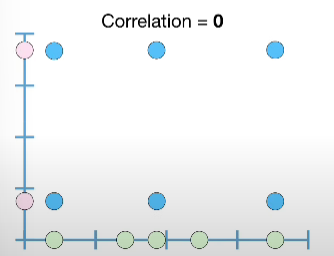
The correlation of a horizontal line is undefined. Because the variance is undefined or 0.
video sources:
- Covariance - a computational step stone for calculating correlation.
- Correlation
covariance
Why Do We Care?
- If there is a linear relationship, we want to make sure the
xis correlated with the resulty. - Want our predictors to be uncorrelated with each other, since each predictor models a different aspect of the overall relationship. If they are correlated, we can end up with redundancy in the model.
Why do we want our predictors to be uncorrelated with each other?
In the
"number of cyclists"
case study, one of the linear regression model contains temp,
and atemp as parameters, they are correlated, and thus the
relationship between that variable and the response is (to some extent) captured
twice in the model. That causes the p-value to be less important.