Neural Network Components
Neural networks reflect the behavior of the human brain, allowing computer programs to recognize patterns and solve common problems in the fields of AI, machine learning, and deep learning.
Artificial neural networks (ANNs) are comprised of a node layers, containing an input layer, one or more hidden layers, and an output layer.
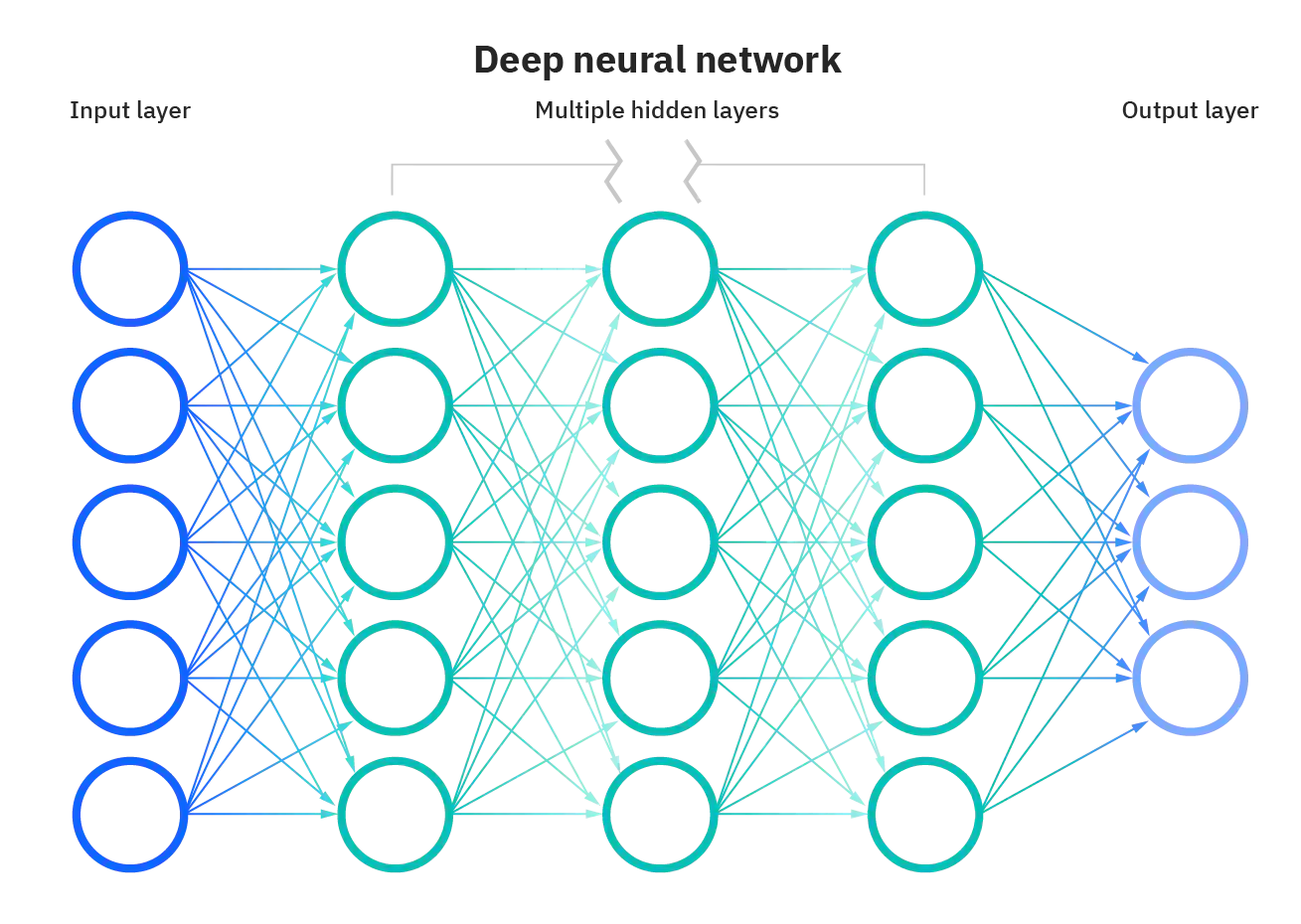
Fully Connected Layers
Every neuron in one layer is connected to every neuron in the next layer. This is achieved by a large matrix multiplication.
Two main steps:
- Linear step:
- Activation step:
has the same shape as . Therefore, transposing is necessary.
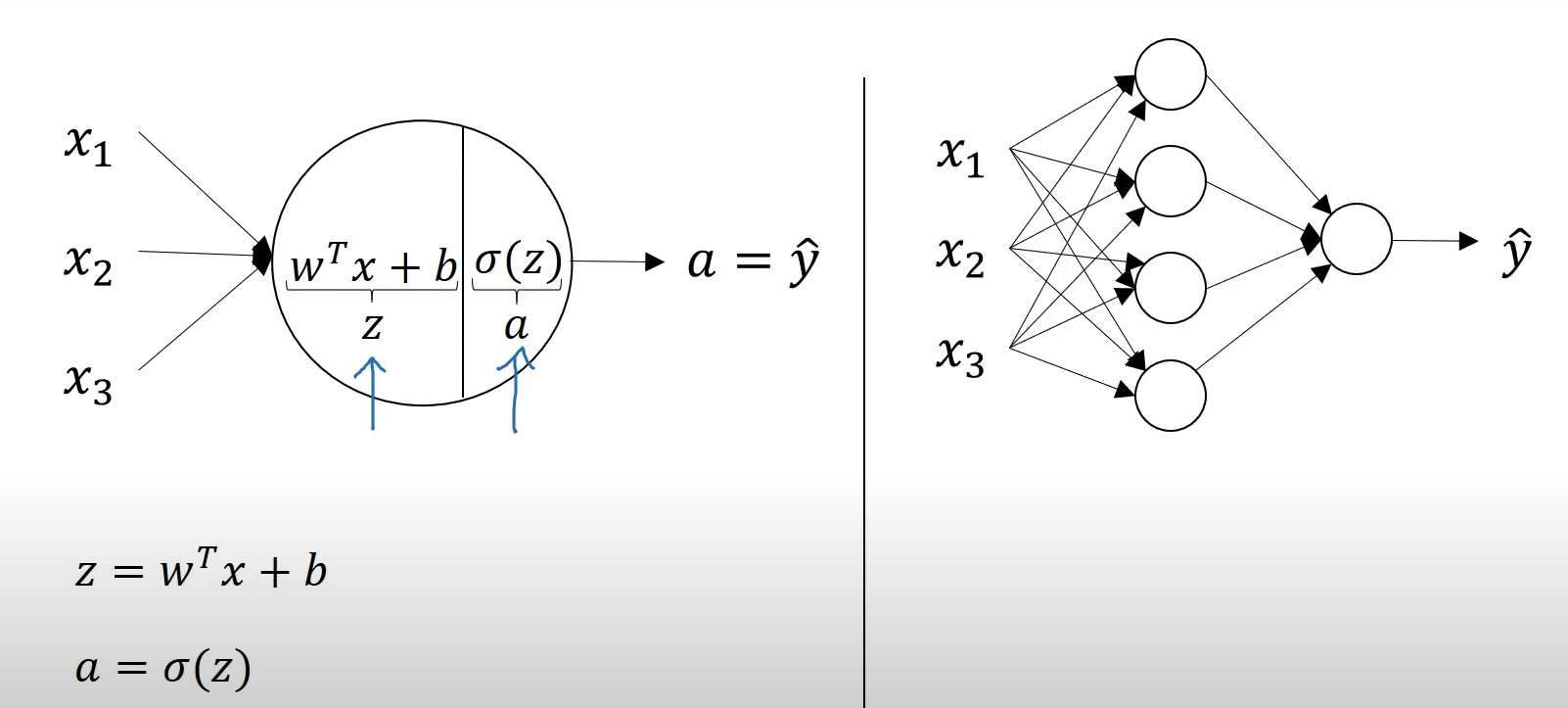
Logistic Regression
Fully Connected Neural Network
Matrix Dimensions
Convolutional Layers
The 2D convolution operation:
- Start with a kernel, which is simply a small matrix of weights;
- The kernel "slides" over the 2D input data, performing an elementwise multiplication with the part of the input the kernel is currently on.
- Summing up the results into a single output pixel.
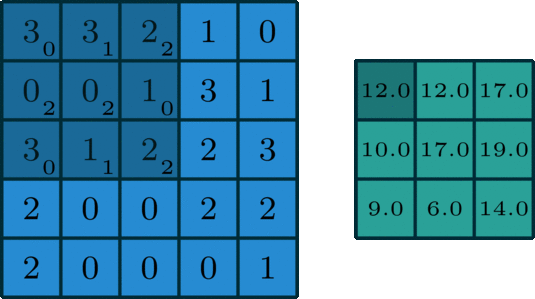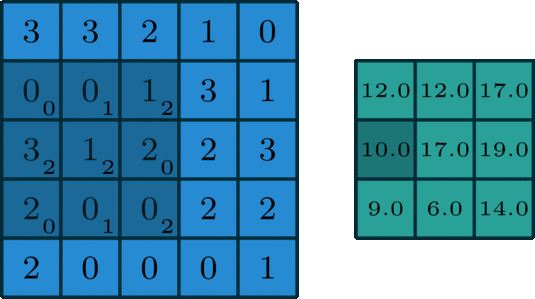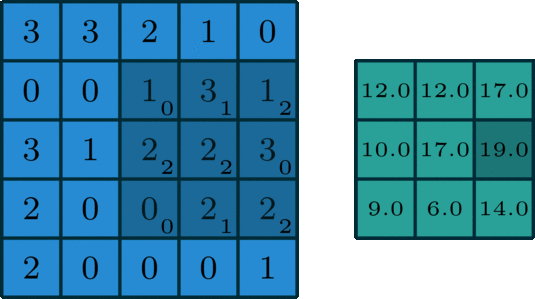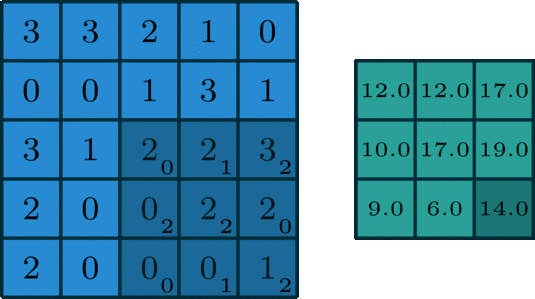
standard convolution
Convolutions over volumes/channels and multiple filters:
Convolutions Over Volumes
Padding
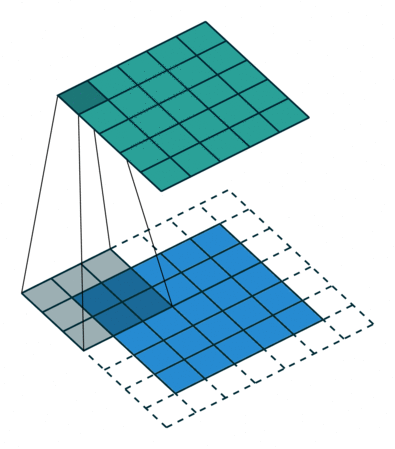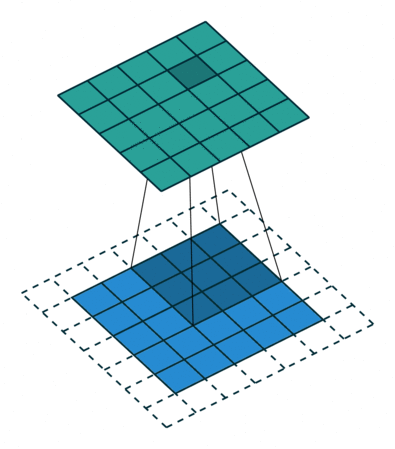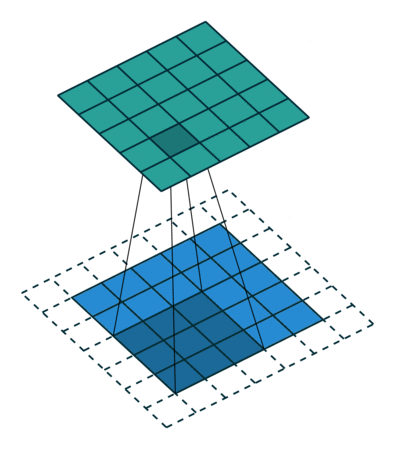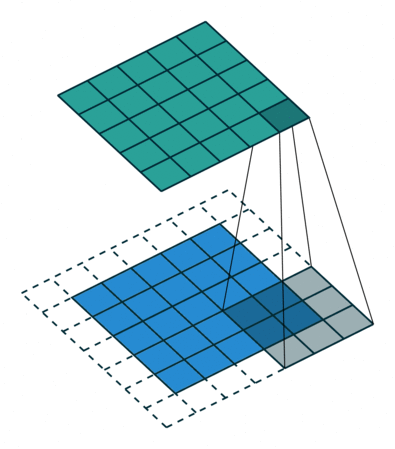
same padding
Pooling Layers
Pooling Operations are used to pool features together, often downsampling the feature map to a smaller size (aka. reduce dimensionality). They can also induce favorable properties such as translation invariance in image classification, as well as bring together information from different parts of a network in tasks like object detection (e.g. pooling different scales).
Hyperparameters:
No parameters to learn.
Pooling Layers
Max Pooling
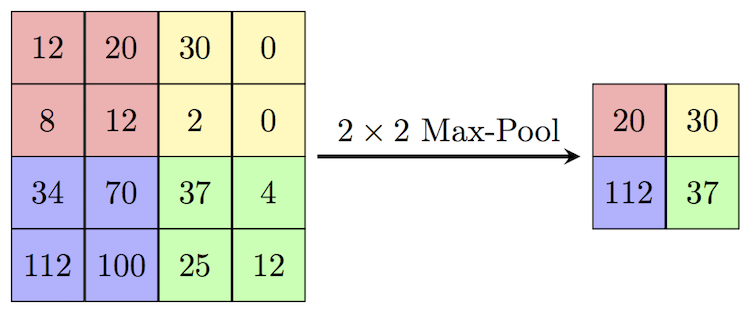
max pooling
Average Pooling
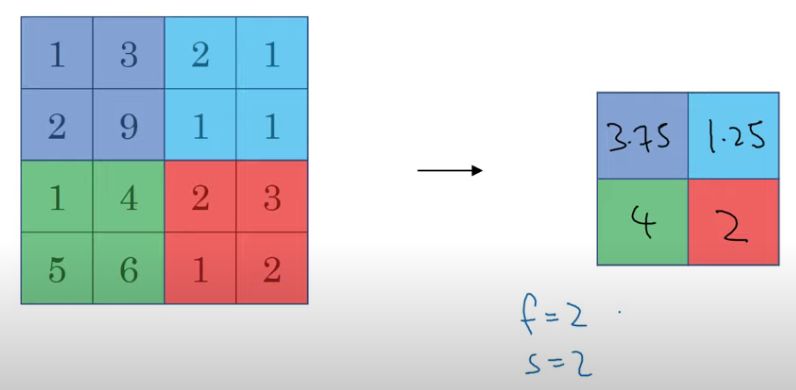
average pooling
Activation Functions
It introduces non-linearties, which is helpful for learning complex patterns.
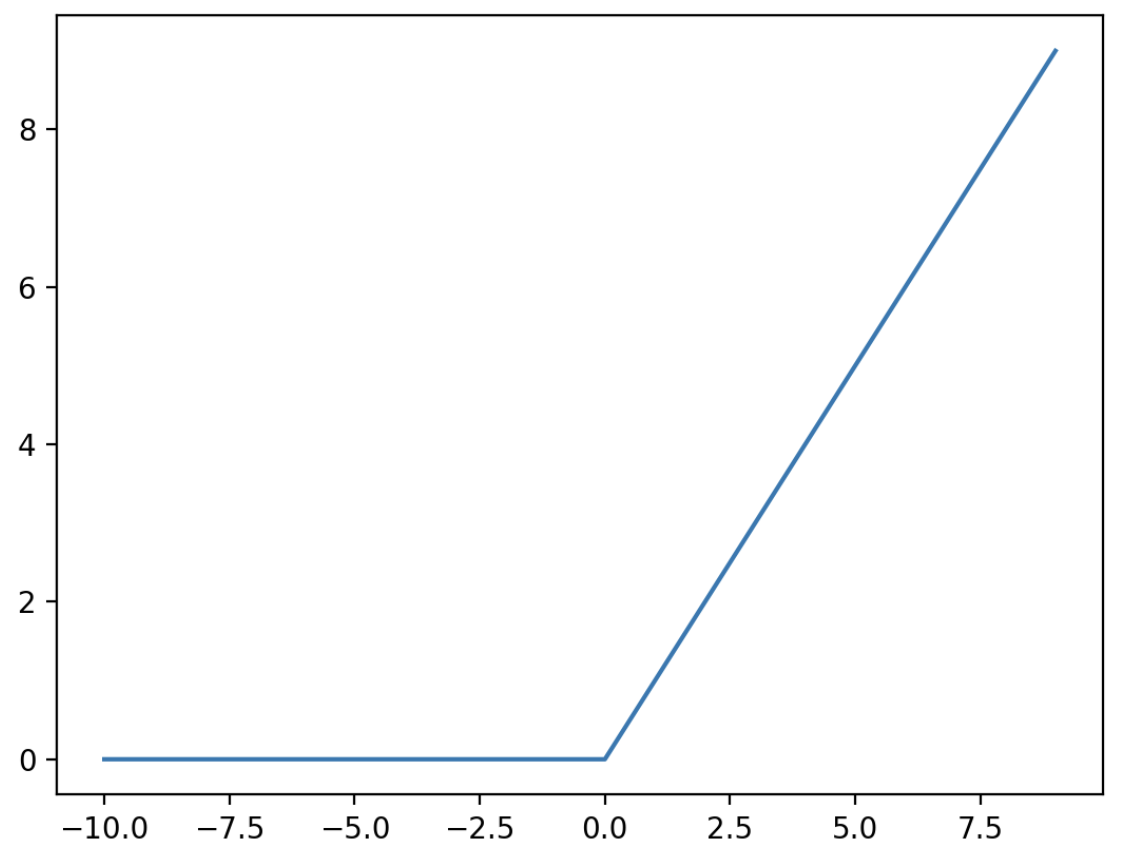
ReLU
Rectified Linear Unit, or ReLU, is a type of activation function that is linear in the positive dimension, but zero in the negative dimension. The kink in the function is the source of the non-linearity.
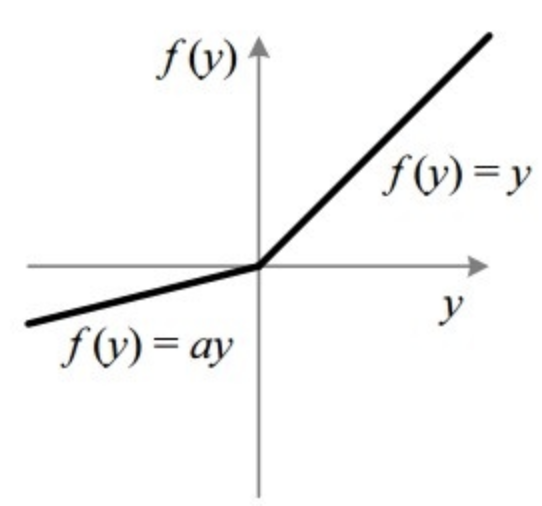
Leaky ReLU
Leaky Rectified Linear Unit, or Leaky ReLU, is a type of activation function based on a ReLU, but it has a small slope for negative values instead of a flat slope. The slope coefficient is determined before training, i.e. it is not learnt during training. This type of activation function is popular in tasks where we we may suffer from sparse gradients, for example training generative adversarial networks.
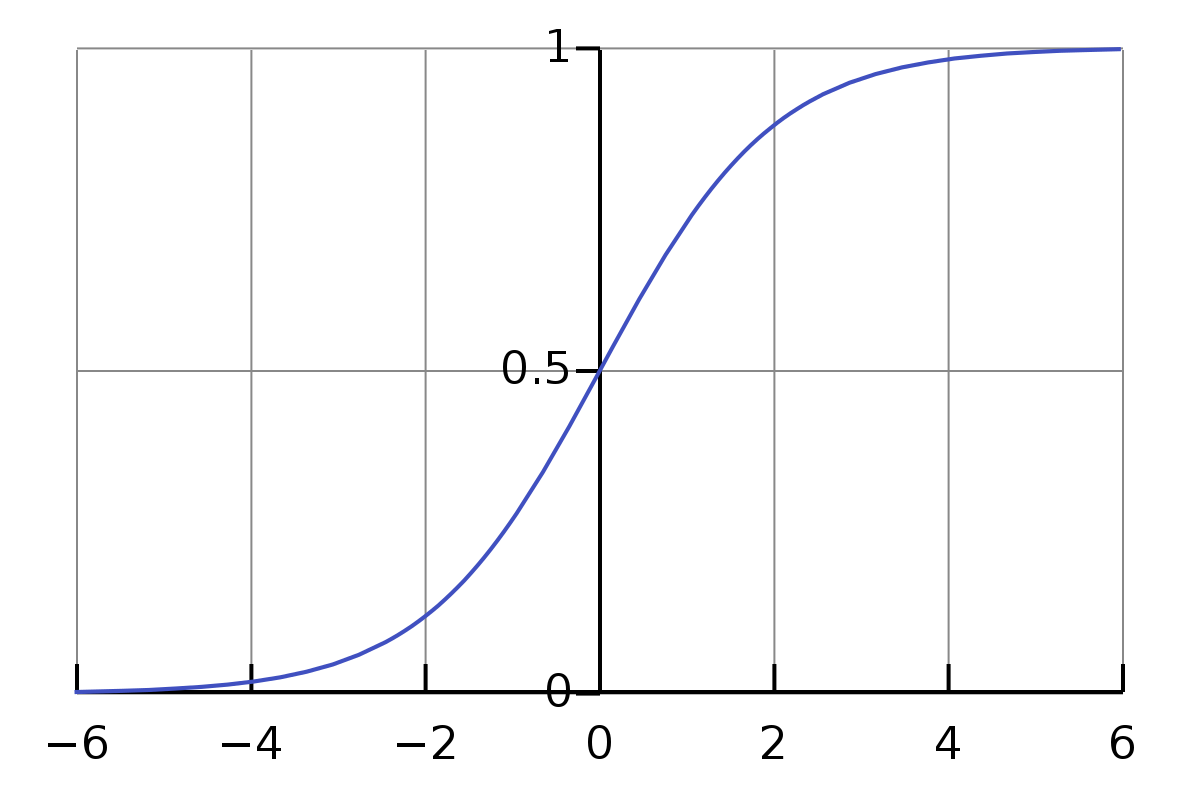
Sigmoid Activation
The output range: [-1, 1].
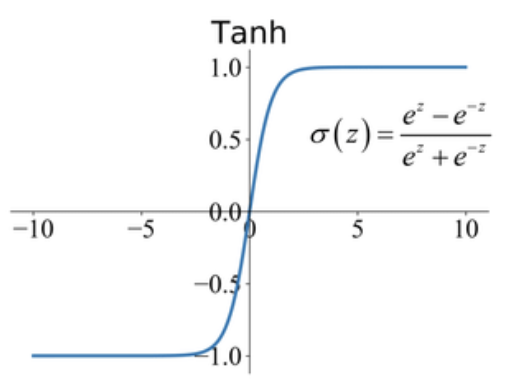
Tanh Activation
Historically, the tanh function became preferred over the sigmoid function as it gave better performance for multi-layer neural networks. But it did not solve the vanishing gradient problem that sigmoid suffered, which was tackled more effectively with the introduction of ReLU activations.
SoftMax Activation
SoftMax
References
- Neural Networks - IBM
- Neural Networks and Deep Learning (Course 1 of the Deep Learning Specialization) - Andrew Ng
- Convolutional Neural Networks (Course 4 of the Deep Learning Specialization) - Andrew Ng
- Intuitively Understanding Convolutions for Deep Learning - towardsdatascience
- Pooling Operations - paperswithcode.com
- Activation Functions - paperswithcode.com
Vocabulary
Cannot find definitions for "induce".
Cannot find definitions for "favorable".
Cannot find definitions for "invariance".